Difference: NGSAlignerDiscussion (1 vs. 5)
Revision 52010-05-28 - jayzhang
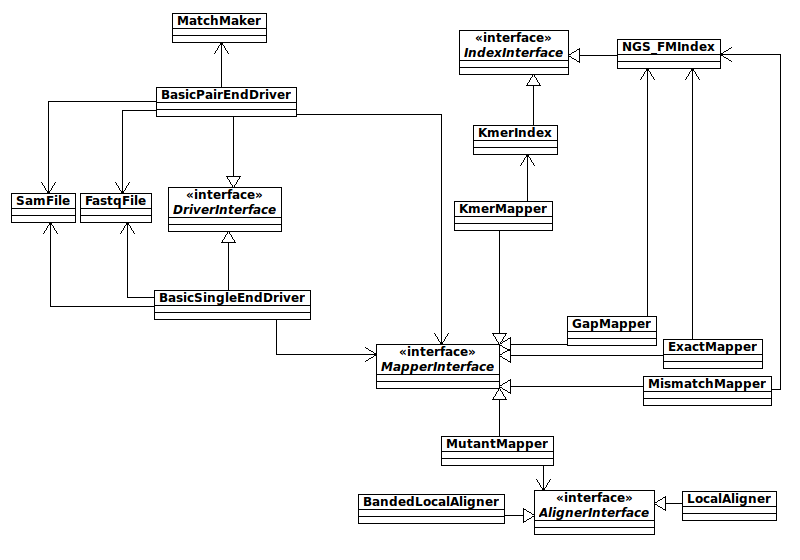 Here's my take on the current UML.
Some points to note:
Here's my take on the current UML.
Some points to note: Revision 42010-05-27 - jujubix
| Line: 1 to 1 | ||||||||
|---|---|---|---|---|---|---|---|---|
Concerning Multimaps | ||||||||
| Line: 38 to 38 | ||||||||
| -- Main.jujubix - 26 May 2010 | ||||||||
| Changed: | ||||||||
| < < |  | |||||||
| > > | 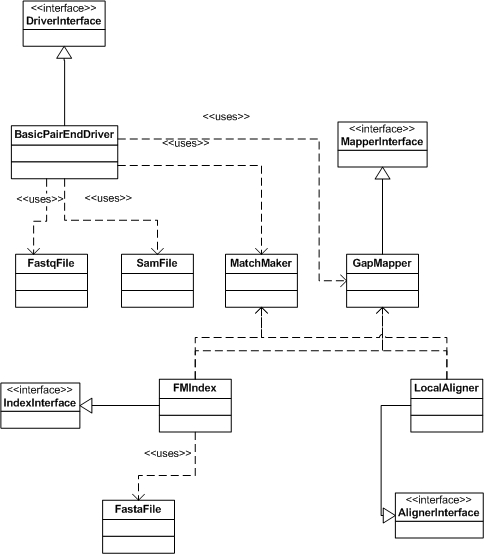 | |||||||
| ||||||||
| Line: 46 to 46 | ||||||||
| ||||||||
| Changed: | ||||||||
| < < |
| |||||||
| > > |
| |||||||
| ||||||||
| Line: 66 to 66 | ||||||||
| -- Main.jujubix - 26 May 2010 | ||||||||
| Changed: | ||||||||
| < < |
| |||||||
| > > |
| |||||||
Revision 32010-05-27 - jujubix
| Line: 1 to 1 | ||||||||
|---|---|---|---|---|---|---|---|---|
Concerning Multimaps | ||||||||
| Line: 38 to 38 | ||||||||
| -- Main.jujubix - 26 May 2010 | ||||||||
| Added: | ||||||||
| > > |
| |||||||
Revision 22010-05-26 - jujubix
| Line: 1 to 1 | ||||||||
|---|---|---|---|---|---|---|---|---|
Concerning Multimaps | ||||||||
| Line: 10 to 10 | ||||||||
| -- Main.jujubix - 21 May 2010 | ||||||||
| Added: | ||||||||
| > > | Concerning the Class HierarchyAs the library starts to take shape, we have to decide upon a class hierarchy which project will be built upon. I imagine that changing the hierarchy down the road will be difficult, so in hopes or avoiding that, let's commit ourselves to a single hierarchy. Some history about the existing hierarchy directories:
| |||||||
Revision 12010-05-21 - jujubix
| Line: 1 to 1 | ||||||||
|---|---|---|---|---|---|---|---|---|
| Added: | ||||||||
| > > |
Concerning MultimapsI sort of came to my conclusion about this already, but I'll spam it here anyway for posterity. When faced when multimaps, there are three modes of resolution: randomly select 1, report all, or report none. Currently, it seems that by default I find all possible mappings, and only during the output phase do I filter to one of the above three (in reality... the latter 2) cases. This isn't very computationally efficient, so I suspect we'll have to adapt something like areport variable found in readaligner.
-- Main.jujubix - 21 May 2010 | |||||||
View topic | History: r5 < r4 < r3 < r2 | More topic actions...
Ideas, requests, problems regarding TWiki? Send feedback