
To specify this graph structure, we create an adjacency matrix:
N = 4; dag = zeros(N,N); dag(1,2) = 1; dag(1,3) = 1; dag(2,4) = 1; dag(3,4) = 1;
We have numbered the nodes as follows: Cloudy = 1, Sprinkler = 2, Rain = 3, WetGrass = 4. The nodes must always be numbered in topological order (i.e., ancestors before descendants). For a more complicated graph, this is a little inconvenient, so we can proceed as follows.
names = {'WetGrass', 'Sprinkler', 'Cloudy', 'Rain'}; % arbitrary order
topology = {'Cloudy', 'Sprinkler'; 'Cloudy', 'Rain'; 'Sprinkler', 'WetGrass'; 'Rain', 'WetGrass'};
[dag, names] = mk_adj_mat(topology, names, 1);
N = length(names);
This will permute 'names' so that they are in a legal topological
ordering.
In this case, names is now {'Cloudy', 'Rain', 'Sprinkler', 'WetGrass'}.
To refer to a node by its name, we must look up its position in this
list using 'stringmatch', e.g., stringmatch('Rain', names) = 2, and then use the
resulting numerical index.
In addition to specifying the graph structure, we must specify the arity of each node. In this case, we will assume they are all binary. Now we are ready to make the Bayes Net.
node_sizes = 2*ones(1,N); bnet = mk_bnet(dag, node_sizes);
for i=1:N
bnet.bnodes{i} = mk_tabular_node(bnet, i);
end
This will create CPTs with random values.
Each CPT is stored as a multidimensional array, where the dimensions are arranged in the same topological order as the nodes, e.g., the CPT for node 4 (WetGrass) is indexed by Sprinkler (2), Rain (3) and then WetGrass (4) itself. Hence the child is always the last dimension. If a node has no parents, its CPT is a column vector representing its prior. Note that in Matlab (unlike C), arrays are indexed from 1, and are layed out in memory such that the first index toggles fastest, e.g., to create the CPT for node 4 (WetGrass)

we can proceed as follows
bnet.bnodes{4}.CPT(1,1,1) = 1.0;
bnet.bnodes{4}.CPT(2,1,1) = 0.1;
...
or, more compactly,
bnet.bnodes{4}.CPT(:) = [1 0.1 0.1 0.01 0 0.9 0.9 0.99];
(Note the colon, which means treat the CPT as a column vector.)
Similarly, for the other nodes, we have
bnet.bnodes{1}.CPT(:) = [0.5 0.5];
bnet.bnodes{2}.CPT(:) = [0.8 0.2 0.2 0.8];
bnet.bnodes{3}.CPT(:) = [0.5 0.9 0.5 0.1];
Now that we have specified all the parameters, we type
bnet = compile_params(bnet);
In the future, I will add a file parser to read one of the standard model specification formats.
obs_nodes = [4]; vals = [2]; [bnet, ll] = enter_evidence(bnet, vals, obs_nodes); m = marginal_nodes(bnet, 3); p = m.T(2);We find that p = Pr(R=2|W=2) = 0.4298. (Note that 1==False, 2==True.) If we have named nodes, we can make the code more readable, as follows:
F = 1; T = 2;
C = stringmatch('Cloudy', names);
S = stringmatch('Sprinkler', names);
R = stringmatch('Rain', names);
W = stringmatch('WetGrass', names);
obs_nodes = [W];
vals = [T];
[bnet, ll] = enter_evidence(bnet, vals, obs_nodes);
m = marginal_nodes(bnet, R);
p = m.T(T);
We find that p = Pr(R=T|W=T) = 0.4298.
Now let us add the evidence that the sprinkler was on.
obs_nodes = [S W]; vals = [T T]; [bnet, ll] = enter_evidence(bnet, vals, obs_nodes); m = marginal_nodes(bnet, R); p = m.T(T);We find that p = Pr(R=T|W=T,S=T) = 0.1945. which is lower than before, because the sprinkler being on can ``explain away'' the fact that the grass is wet.
BNT uses the junction tree algorithm for (exact) inference. For
details, I recommend
"Inference in Belief Networks: A procedural guide",
C. Huang and A. Darwiche,
Intl. J. Approximate Reasoning, 15(3):225-263, 1996.
For details on inference in Bayes nets with both discrete and
continuous variables, click here.
nsamples = 50;
samples = sample_bnet(bnet, nsamples);
seed = 0;
bnet2 = randomize_params(bnet, seed);
% hide 20% of the nodes
nnodes = 4;
hide = rand(nsamples, nnodes) > 0.8;
vals = cell(1, nsamples);
obs = cell(1, nsamples);
for i=1:nsamples
obs{i} = find(~hide(i,:));
vals{i} = samples(i, obs{i});
end
max_iter = 10;
[bnet3, LL] = learn_params(bnet2, vals, obs, max_iter);
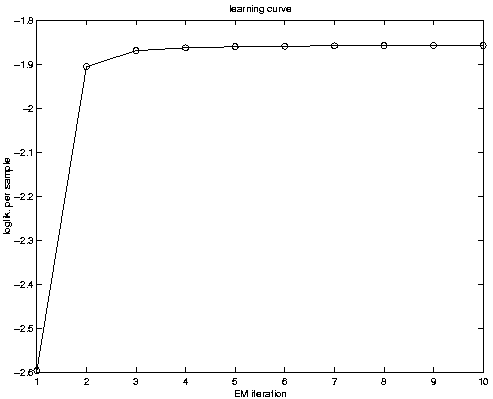
plot(LL / nsamples,'o-'); % plot the learning curve
Here is the
learning curve.
Also, let's compare the original and learned CPTs for node 4.
dispcpt(bnet.bnodes{4}.CPT)
1 1 : 1.0000 0.0000
2 1 : 0.1000 0.9000
1 2 : 0.1000 0.9000
2 2 : 0.0100 0.9900
dispcpt(bnet3.bnodes{4}.CPT)
1 1 : 1.0000 0.0000
2 1 : 0.2261 0.7739
1 2 : 0.3629 0.6371
2 2 : 0.0036 0.9964
To add a uniform Dirichlet prior with effective sample size of 0.01,
we can initialize the nodes as follows.
ess = 0.01;
for i=1:N
bnet.bnodes{i} = mk_tabular_node(bnet, i, ess);
end
This will avoid estimating a parameter as 0 just because there is
insufficient training data.
For more details on learning in the BNT, click here

| 
|
Thus X is the observed input, Y is the output, and the Q nodes are hidden "gating" nodes, which select the appropriate set of parameters for Y. During training, Y is assumed observed, but for testing, the goal is to predict Y given X. Note that this is a conditional density model, so we don't associate any parameters with X. The HME model is essentially a probabilistic decision tree of fixed height.
As a concrete example, consider the mixture of experts model where X and Y are scalars, and Q is binary. This is just piecewise linear regression, where we have two line segments, i.e.,

We can create this model as follows.
sigma = 1;
dag = zeros(3,3);
dag(1,2) = 1; dag(1,3) = 1;
dag(2,3) = 1;
ns = [1 2 1]; % node sizes
discrete_nodes = [2]; % the rest are assumed continuous
bnet = mk_bnet(dag, node_sizes, discrete_nodes);
bnet.bnodes{1} = mk_input_node(bnet, 1); % no parameters for node 1
bnet.bnodes{2} = mk_softmax_node(bnet, 2); % could also use logistic
bnet.bnodes{3} = mk_gaussian_node(bnet, 3); % observed
bnet = compile_params(bnet);
Now let us fit this model using EM. First we load the 200 training cases and plot them.
load data -ascii; plot(data(:,1), data(:,2), '.');

Now we clamp the variance of the output node to 1, and randomize all the other parameters.
sigma = 1;
bnet.bnodes{3}.cov = sigma*ones(ns(3), ns(3), ns(2)); % |Y|*|Y|*|Q| matrix
bnet.bnodes{3}.adjustable_cov = 0;
seed = 0;
bnet = randomize_params(bnet, seed);
bnet = compile_params(bnet);
This is the performance of the initial model.

Now let's train the model, and plot the final performance.
max_iter = 20; obs_nodes = [1 3]; bnet = learn_params(bnet, data, obs_nodes, max_iter);

Since this model has such a simple structure, it is possible to explicitely derive the EM equations: see Hierarchical mixtures of experts and the EM algorithm M. I. Jordan and R. A. Jacobs. Neural Computation, 6, 181-214, 1994.

| 
| 
| 
|
Let us now create the FA model using the toolbox.
ns = [q p];
dag = zeros(2,2);
dag(1,2) = 1;
dnodes = [];
onodes = 2;
bnet = mk_bnet(dag, ns, dnodes);
bnet.bnodes{1} = mk_gaussian_node(bnet, 1);
bnet.bnodes{1}.mean = zeros(q,1);
bnet.bnodes{1}.cov = eye(q);
bnet.bnodes{1}.adjustable = 0; % FA requires that X ~ N(0, I)
bnet.bnodes{2} = mk_gaussian_node(bnet, 2);
bnet.bnodes{2}.mean = mu;
bnet.bnodes{2}.cov = diag(Psi);
bnet.bnodes{2}.cov_type = 'diag';
bnet.bnodes{2}.weights = W;
bnet = compile_params(bnet);
We can compute Maximum Likelihood (ML) estimates of W, Psi and mu
using EM: just call learn_params.
(Zoubin Ghahramani has matlab
code
for learning FA and MFA models, which is faster, but less flexible,
than using BNT.)
Not surprisingly, the ML estimates for mu and Psi turn out to be
identical to the
sample mean and variance, which can be computed directly as
mu_ML = mean(data); Psi_ML = diag(cov(data));Note that W can only be identified up to a rotation matrix, because of the spherical symmetry.
Probabilistic Principal Components Analysis (PPCA) is the special case in which all the elements of Psi are the same (spherical noise), i.e., Psi = sigma I. In this case, there is a closed-form solution for W as well, i.e., we do not need to use EM. In particular, W contains the first |X| eigenvectors of the sample covariance matrix, with scalings determined by the eigenvalues and s. We can recover "classical" PCA in the s->0 limit. For details, see Tipping and Bishop, "Mixtures of probabilistic principal component analyzers" Neural Computation 11(2):443--482, 1999 and "EM algorithms for PCA and SPCA", Sam Roweis, NIPS 97. (Sam also has specialized matlab code for the PPCA model.) In the mixture case, we can compute the "responsibilities" of the mixing components in the E step, and take a weighted combination of the eigenvalues in the M step.
Independent Factor Analysis (IFA) generalizes FA by allowing a non-Gaussian prior on each component of X. (Note that we can approximate a non-Gaussian prior using a mixture of Gaussians.) This means that the likelihood function is no longer rotationally invariant, so we can uniquely identify W and the hidden sources X. IFA also allows a non-diagonal Psi (i.e. correlations between the components of Y). We recover classical Independent Components Analysis (ICA) in the Psi -> 0 limit, and by assuming that |X|=|Y|, so that the weight matrix W is square and invertible. For details, see Independent Factor Analysis, H. Attias, Neural Computation 11: 803--851, 1998.
Let us create the following small MRF.
1 - 2 - 3 | | | 4 - 5 - 6 | | | 7 - 8 - 9where all nodes are hidden and binary, and all potentials are random.
R = 3; C = 3; N = R*C;
H = reshape(1:N, [R C]); % H(i,j) = k means hidden node i,j has number k
arity = 2;
ns = arity*ones(1,N);
% Create the undirected graph
G = zeros(N,N);
for r=1:R
for c=1:C
if r>1, G(H(r,c), H(r-1,c)) = 1; end % north
if c1, G(H(r,c), H(r,c-1)) = 1; end % west
end
end
% Create the unique pairwise potentials
T = {};
cliques = {};
k = 1;
GG = triu(G); % so we don't get 1->4 and 4->1 etc.
for i=1:N
hood = find(GG(i,:));
for j=hood
cliques{k} = [i j];
dom = cliques{k};
T{k} = mk_table(dom, ns(dom));
T{k}.T = myrand(ns(dom));
k = k + 1;
end
end
P = length(T); % num. pairs
dag = zeros(N,N);
dnodes = 1:N;
eclass = 1:N;
onodes = [];
bnet = mk_bnet(dag, ns, dnodes, 'jtree', eclass, onodes, G, cliques);
for i=1:N
bnet.bnodes{i} = mk_input_node(bnet, i); % so no CPTs needed
end
for i=1:P
bnet.clpot{i} = T{i};
end
bnet = compile_params(bnet);
Now suppose node 1's child (not shown) is observed, and returns a
likelihood vector [0.3 0.7]. We can compute the marginal on node 2 as
follows.
obs = [];
vals = [];
soft_obs = 1;
soft_vals = { [0.3 0.7] };
[bnet, ll] = enter_evidence(bnet, obs, vals, soft_vals, soft_obs);
m = marginal_nodes(bnet, 2);
post = m.T(:)';

|  
|

|  
|
Let us create an HMM using the toolbox.
ss = 2; % slice size
intra = zeros(ss, ss);
intra(1,2) = 1;
inter = zeros(ss, ss);
inter(1,1) = 1;
node_sizes = [2 4]; % 2 hidden states, 4 output symbols
dnodes = [1 2];
eclass = [1 2 3 2];
obs_nodes = [2];
bnet = mk_dbn(intra, inter, node_sizes, dnodes, eclass, obs_nodes);
for i=1:length(bnet.bnodes)
bnet.bnodes{i} = mk_tabular_node(bnet, i);
end
seed = 0;
bnet = randomize_params(bnet, seed);
The equivalence class reflects the fact that the parameters for the sensor model Pr(Y(t)|Q(t)) are shared (tied) across all time slices, as are the parameters of the state evolution model, Pr(Q(t+1)|Q(t)), for t>1. That is nodes 2, 4, 6, ... are parametrically equivalent, as are 3, 5, 7, ..., where we have numbered the nodes from top to bottom, left to right. Thus bnodes{i} refers to the i'th equivalence class, which may not be the same as the i'th node.
Let's try generating some data from this model, randomizing the parameters, and learning it back. First we generate some data.
seed = 1;
rand('state', seed);
T = 5;
ntrain = 3;
vals = cell(1, ntrain);
for i=1:ntrain
sample = sample_dbn(bnet, T);
vals{i} = sample(obs_nodes, :);
end
This is what the training data looks like
celldisp(vals)
vals{1} =
1 2 4 1 2
vals{2} =
4 4 2 4 4
vals{3} =
2 1 1 3 1
(We use a cell array to allow for variable length sequences.)
Now we run EM.
bnet1 = randomize_params(bnet, 2); max_iter = 5; [bnet2, ll2] = learn_params(bnet1, vals, obs_nodes, max_iter);Let's check that this gives the same results as using my HMM toolbox.
[prior1, transmat1, obsmat1] = dbn_to_hmm(bnet1); [ll3, prior3, transmat3, obsmat3] = learn_hmm(vals, prior1, transmat1, obsmat1, max_iter); [prior2, transmat2, obsmat2] = dbn_to_hmm(bnet2); assert(approxeq(ll3, ll2)); assert(approxeq(prior3(:), prior2(:))); assert(approxeq(transmat3, transmat2)); assert(approxeq(obsmat3, obsmat2));(We use approxeq instead of isequal to ignore roundoff errors.) For more details, see the file hmm1 in the examples directory.

We can create this topology using the function mk_bat_topology in the examples directory.
[intra, inter, node_sizes, onodes, names] = mk_bat_topology;In a complicated DBN such as this, it is tedious to specify the equivalence classes by hand, so you can use
eclass = mk_equiv_classes_for_dbn(inter, intra);This will tie the observation and transition parameters as in an HMM, even though the observed and hidden state variables are decomposed into separate nodes.
Exact inference in large DBNs is intractable, so we can use the approximation algorithm described in Tractable inference for complex stochastic processes , Boyen and Koller, UAI 1998 and Approximate learning of dynamic models, Boyen and Koller, NIPS 1998. This approximates the belief state with a product of marginals on a specified set of clusters. For example, let us use the clusters indicated by the dotted lines in the figure.
ss = length(intra); % slice size
dnodes = 1:ss; % we assume all nodes are discrete
clusters = cell(1,2);
clusters{1} = [stringmatch({'LeftClr', 'RightClr', 'LatAct', 'Xdot', 'InLane'}, names)];
clusters{2} = [stringmatch({'FwdAct', 'Ydot', 'Stopped', 'EngStatus', 'FBStatus'}, names)];
bnet{1} = mk_dbn(intra, inter, node_sizes, dnodes, eclass, onodes, 'bk', clusters);
for i=1:length(bnet{1}.bnodes)
bnet{1}.bnodes{i} = mk_tabular_node(bnet{1}, i);
end
Now we will generate a short random sequence and compute the posterior
on the LatAct node.
T = 4;
rand('state',0);
vals = sample_dbn(bnet{1}, T);
bnet{1} = enter_evidence(bnet{1}, vals(onodes,:));
i = stringmatch('LatAct', names);
for t=1:T
marg = marginal_nodes(bnet{1}, i, t);
post1(t) = marg.T(2);
end
Let us compare this with the result of doing exact inference.
bnet{2} = change_algo(bnet{1}, 'bk', 'exact');
bnet{2} = enter_evidence(bnet{2}, vals(onodes,:));
for t=1:T
marg = marginal_nodes(bnet{2}, i, t);
post2(t) = marg.T(2);
end
post1
0.4795 0.6760 0.6454 0.2800
post2
0.4795 0.6746 0.6676 0.2800
So we see that the approximation is very good. In this case, exact
inference takes about 1 minute (for 4 time slices), which is 3 times
slower than approximate inference.
While both algorithms are slow, bear in mind that the BAT net has a
hidden state space of size 2^18.
Of course, it would be possible to speed both algorithms up by a large
constant factor if we implemented certain optimizations; however, the
emphasis has been on keeping the code simple and easy to read.
Generating model-specific
C code (as in BUGS) would be the fastest, as I do for the likelihood
weighting and sof algorithms.
x(t+1) = A*x(t) + w(t), w ~ N(0, Q), x(0) ~ N(init_x, init_V) y(t) = C*x(t) + v(t), v ~ N(0, R)
Hence we can create an LDS as follows.
intra = zeros(2); intra(1,2) = 1;
inter = zeros(2); inter(1,1)=1;
lX = 2; lY = 3;
node_sizes = [lX lY];
obs_nodes = [2];
discrete_nodes = [];
equiv_class = [1 2 3 2];
bnet = mk_dbn(intra, inter, node_sizes, discrete_nodes, equiv_class, obs_nodes);
for i=1:length(bnet.bnodes)
bnet.bnodes{i} = mk_gaussian_node(bneth, i, 'full');
end
bnet.bnodes{1}.mean = init_x;
bnet.bnodes{1}.cov = init_V;
bnet.bnodes{2}.mean = zeros(lY, 1);
bnet.bnodes{2}.cov = R;
bnet.bnodes{2}.weights = C;
bnet.bnodes{3}.mean = zeros(lX, 1);
bnet.bnodes{3}.cov = Q;
bnet.bnodes{3}.weights = A;
bnet = compile_params(bnet);
Running the junction tree algorithm on this model is equivalent to
doing full smoothing. If you just want to do filtering, set
bnet.filter_only = 1;By default, when you create a DBN, the BNT will use the BK algorithm in exact mode for inference. However, you can tell it to use the special purpose code in my Kalman Filter Toolbox as follows:
bnet = mk_dbn(intra, inter, node_sizes, discrete_nodes, equiv_class, obs_nodes, 'lds');This should give exactly the same results, but will be faster. See the file kalman1 in the examples directory for details.
It is also straightforward to create a Switching Kalman Filter (i.e., a piecewise-linear dynamical system) by adding a hidden discrete node, as in the following picture.

| 
| 
| 
|
I have adopted an object-oriented design philosophy. There are two main kinds of objects: nodes and potentials. The node types are {gaussian, input, logistic, noisyfn, noisyor, softmax, tabular}. Each node type must implement various abstract operations, such as 'sample_xxx_node', 'maximize_params_xxx_node', etc. See the bnode directory for a complete list of operations. If you add a new node type, you should specify how to perform each of these operations.
Potentials are only necessary for the junction tree algorithm. There are four types: tables, max_tables, Gaussian and cg (conditional Gaussian). (A max_table is just like a table except the * operator is replaced by max.) Each potential must implement the following operations: marginalize, multiply, divide, scale, and normalize. (Scaling is used to prevent underflow.) You probably won't need to add any new potential types, but for each node type you add, you must specify how to convert it to each of these potential types.
It is fairly simple to add a new inference algorithm. Simply call it from inside enter_evidence, and modify marginal_nodes so it knows where to extract the results of inference. This will seamlessly integrate with the rest of the package (e.g., the learning routines, which call inference as a subroutine).
{kind=link}