Section 4: Iterating over Directory Trees
Assuming that we take time to store files in an organized way and create subdirectories (i.e., folders) to store files associated with different projects, courses and/or applications, our files end up stored in a tree of directories.
In previous sections we learned how to read and write data to/from files. There will be situations where we want to process data stored in a number of separate files contained in a certain subtree of directories. In other words, we want to traverse a directory tree and process each of the files that we encounter, or perhaps just those files with a certain extension.
The
os package of the Python library contains a function
named walk that is very useful in this context. The
function consumes the path to the root of a directory and,
for each directory in the tree rooted at root, yields a
tuple of length 3 of the form:(dirpath, dirnames, filenames)where
dirpath is the path to the current directory, dirnames
is a list of the names of immediate subdirectories, and filenames
is a list of the names of files in the current directory. Note that
a tuple is similar to a list in that it represents data of arbitrary size
and you can iterate over each of the items in the tuple using a for-each
loop. However, a tuples differs from a list in that it is immutable
so, you cannot modify the tuple once it's been created. An example will help to illustrate how this function works. Consider the directory structure pictured in Figure 7.1:
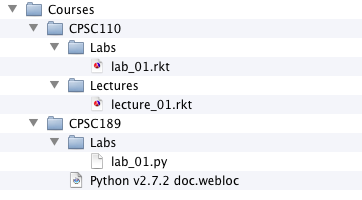
Figure 7.1
We assume that the
Courses directory is located in the Documents
directory of a user named chris. Note that each file
or directory has a path that describes how to navigate to that file or
directory from the root of the file system. So, for example, the
root folder Courses is found at:
/Users/chris/Documents/Courses
whereas the
Labs directory of the CPSC189
directory is found at:
/Users/chris/Documents/Courses/CPSC189/Labs
Let's design a Python function that prints to the screen the data that
os.walk yields at each directory that it visits. We have
already seen that this function yields compound data, so a template for
such a function will look like:for dirinfo in os.walk(root):
fn_for_dirinfo(dirinfo)
where
dirinfo is a tuple of length 3 as discussed
earlier. In our case, fn_for_dirinfo will be print_dirinfo.
Our output will be much more readable if we indent it based on the length of the path to the directory whose information we are currently printing. So, for the directory tree pictured in Figure 7.1, we expect the following output:
/Users/chris/Documents/Courses
- Directories:
CPSC110
CPSC189
- Files:
.DS_Store
/Users/chris/Documents/Courses/CPSC110
- Directories:
Labs
Lectures
- Files:
.DS_Store
/Users/chris/Documents/Courses/CPSC110/Labs
- Directories:
- Files:
lab_01.rkt
/Users/chris/Documents/Courses/CPSC110/Lectures
- Directories:
- Files:
lecture_01.rkt
/Users/chris/Desktop/temp/Courses/CPSC189
- Directories:
Labs
- Files:
.DS_Store
Python v2.7.2 doc.webloc
/Users/chris/Desktop/temp/Courses/CPSC189/Labs
- Directories:
- Files:
lab_01.py
Take a few moments to compare the output that you see here with the graphical depiction of the directory tree presented in Figure 7.1.
First, let's observe the order in which directories in this tree were visited:
/Users/chris/Documents/Courses
/Users/chris/Documents/Courses/CPSC110
/Users/chris/Documents/Courses/CPSC110/Labs
/Users/chris/Documents/Courses/CPSC110/Lectures
/Users/chris/Documents/Courses/CPSC189
/Users/chris/Documents/Courses/CPSC189/Labs- a depth-first rather than breadth-first ordering.
Now observe that for each directory visited, we print the path to that directory, the list of directories contained in that directory and the list of files. So, for example, when visiting the directory
/Users/chris/Documents/Courses/CPSC189we print the path just listed above and then we see the following list of directories contained within that directory:
Labsand the following list of files:
.DS_Store
Python v2.7.2 doc.weblocNote that the list of files in this and other directories includes
.DS_Store. This file does not appear in Figure 7.1 as it is
a hidden system file (Mac OS/X only). Before we present the final code, let's consider how to handle the indentation. The number of levels in the directory tree is directly proportional to the number of times the path component separator appears in the path. The path component separator depends on the particular operating system. For Unix and OS/X systems, it is the character
'/'
whereas for Windows systems it is '\'. The separator
for the particular system on which a Python program is running is
represented by the constant os.sep found in the os
package of the standard Python library. Hence, an appropriate level
of indentation can be specified by counting the number of times os.sep
occurs in the path to the directory we are currently visiting and
subtracting the number of times this character appears in the path to the
root of the subtree under consideration.So, for example, if we want to traverse the subtree rooted at
/Users/chris/Documents/Courses
and we are currently visiting the directory
/Users/chris/Documents/Courses/CPSC189/Labsan appropriate level of indentation is given by:
(number of
'/' in path to current) - (number of '/'
in path to root)
= 6 - 4 = 2
The first version of our program is presented in Code Explorer 7.3. Note that the
print_dir_info
function pulls apart the compound data stored in the tuple dir_info.
It then calls a helper function to process each part. Note that the
implementation of the find_indent function makes use of the
fact that in Python the product of an integer n and a string
my_str produces a string that consists of n
copies of my_str. So, 3 * 'hello'
produces the string 'hellohellohello'. print_dirnames and print_filenames
look very similar. Perhaps this is not surprising as each takes a
list of strings representing a list of file system components (files or
directories) and prints them on the screen. Let's circle the points
of variation: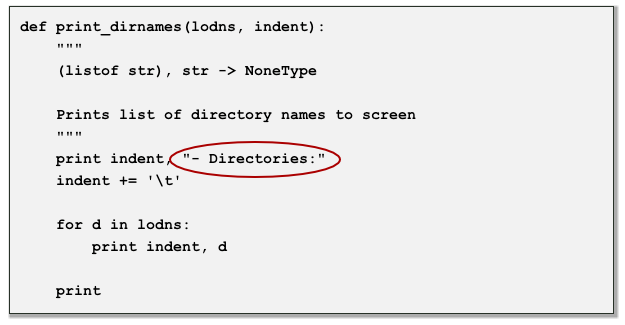
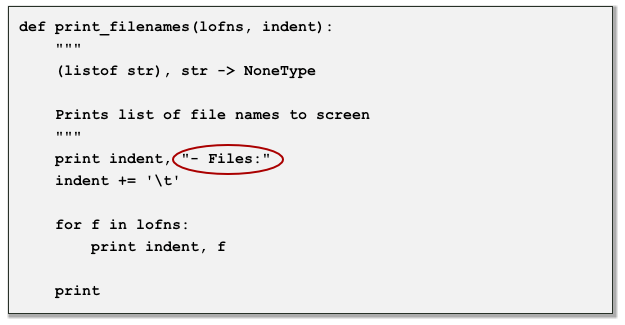
and then parameterize the point of variation to produce a more abstract function:
def print_componentnames(lons, indent, label):
"""
(listof str), str, str -> NoneType
Prints list of component names to screen
"""
print indent, label
indent += '\t'
for n in lons:
print indent, n
The final version of the code is presented in Code Explorer 7.4.