Third edition of Artificial Intelligence: foundations of computational agents, Cambridge University Press, 2023 is now available (including the full text).
5.2.2.2 Top-Down Proof Procedure
An alternative proof method is to search backward or top-down from a query to determine if it is a logical consequence of the given definite clauses. This procedure is called propositional definite clause resolution or SLD resolution, where SL stands for Selecting an atom using a Linear strategy, and D stands for Definite clauses. It is an instance of the more general resolution method.
The top-down proof procedure can be understood in terms of answer clauses. An answer clause is of the form
where yes is a special atom. Intuitively, yes is going to be true exactly when the answer to the query is "yes."
If the query is
ask q1∧...∧qm.
the initial answer clause is
yes ←q1∧...∧qm.
Given an answer clause, the top-down algorithm selects an atom in the body of the answer clause. Suppose it selects ai. The atom selected is called a goal. The algorithm proceeds by doing steps of resolution. In one step of resolution, it chooses a definite clause in KB with ai as the head. If there is no such clause, it fails. The resolvent of the above answer clause on the selection ai with the definite clause
is the answer clause
That is, the goal in the answer clause is replaced by the body of the chosen definite clause.
An answer is an answer clause with an empty body (m=0). That is, it is the answer clause yes←.
An SLD derivation of a query "ask q1∧...∧qk" from knowledge base KB is a sequence of answer clauses γ0, γ1, ..., γn such that
- γ0 is the answer clause corresponding to the original query, namely the answer clause yes←q1∧...∧qk;
- γi is the resolvent of γi-1 with a definite clause in KB; and
- γn is an answer.
Another way to think about the algorithm is that the top-down algorithm maintains a collection G of atoms to prove. Each atom that must be proved is a goal. Initially, G is the set of atoms in the query. A clause a ←b1∧...∧bp means goal a can be replaced by goals b1,...,bp. Each bi is a subgoal of a. The G to be proved corresponds to the answer clause yes←G.
2: Inputs
3: KB: a set of definite clauses
4: Query: a set of atoms to prove
5: Output
6: yes if KB
 Query and the procedure fails otherwise
Query and the procedure fails otherwise
7: Local
8: G is a set of atoms
9: G←Query
10: repeat
11: select an atom a in G
12: choose definite clause "a←B" in KB with a as head
13: replace a with B in G
14: until G={}
15: return yes
The procedure in Figure 5.4 specifies a procedure for solving a query. It follows the definition of a derivation. In this procedure, G is the set of atoms in the body of the answer clause. The procedure is non-deterministic in that a point exists in the algorithm where it has to choose a definite clause to resolve against. If there are choices that result in G being the empty set, it returns yes; otherwise it fails.
This algorithm treats the body of a clause as a set of atoms; G is also a set of atoms. It can be implemented by treating G as a set, where duplicates are removed. It can also be implemented with G as an ordered list of atoms, perhaps with an atom appearing a number of times.
Note that the algorithm requires a selection strategy of which atom to select at each time. It does not have to search over the different selections, but the selections affect the efficiency. One common selection strategy is to select the leftmost atom in some ordering of the atoms. This is not a fair strategy; it is possible for it to get into an infinite loop, when a different strategy would fail. The best selection strategy is to select the atom that is most likely to fail.
b←d∧e.
b←g∧e.
c←e.
d.
e.
f←a∧g.
It is asked the following query:
The following shows a derivation that corresponds to the sequence of assignments to G in the repeat loop of Figure 5.4. We assume that G is represented as an ordered list, and it always selects the leftmost atom in G:
yes←b∧c.
yes←d∧e∧c.
yes←e∧c.
yes←c.
yes←e.
yes←.
The following shows a sequence of choices, where the second definite clause for b was chosen, which fails to provide a proof:
yes←b∧c.
yes←g∧e∧c.
If g is selected, there are no rules that can be chosen. This proof attempt is said to fail.
When the top-down procedure has derived the answer, the rules used in the derivation can be used in a bottom-up proof procedure to infer the query. Similarly, a bottom-up proof of an atom can be used to construct a corresponding top-down derivation. This equivalence can be used to show the soundness and completeness of the top-down proof procedure. As defined, the top-down proof procedure may spend extra time re-proving the same atom multiple times, whereas the bottom-up procedure proves each atom only once. However, the bottom-up procedure proves every atom, but the top-down procedure proves only atoms that are relevant to the query.
The non-deterministic top-down algorithm of Figure 5.4 together with a selection strategy induces a search graph, which is a tree. Each node in the search graph represents an answer clause. The neighbors of a node yes ←a1∧...∧am, where ai is the selected atom, represent all of the possible answer clauses obtained by resolving on ai. There is a neighbor for each definite clause whose head is ai. The goal nodes of the search are of the form yes ←.
a←b∧c. a←g. a←h. b←j. b←k. d←m. d←p. f←m. f←p. g←m. g←f. k←m. h←m. p.
and the query
The search graph for an SLD derivation, assuming the leftmost atom is selected in each answer clause, is shown in Figure 5.5.
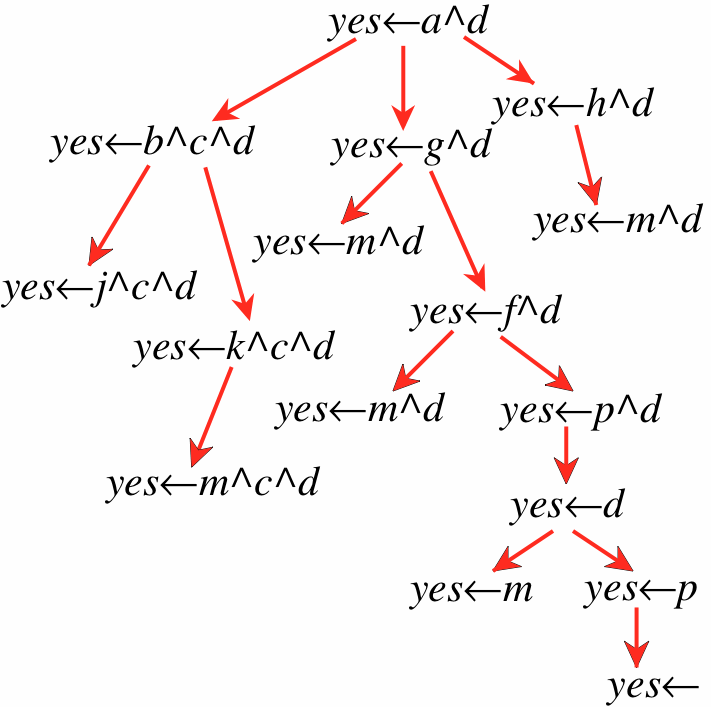
For most problems, the search graph is not given statically, because this would entail anticipating every possible query. More realistically, the search graph is dynamically constructed as needed. All that is required is a way to generate the neighbors of a node. Selecting an atom in the answer clause defines a set of neighbors. A neighbor exists for each rule with the selected atom as its head.
Any of the search methods of Chapter 3 can be used to search the search space. Because we are only interested in whether the query is a logical consequence, we just require a path to a goal node; an optimal path is not necessary. There is a different search space for each query. A different selection of which atom to resolve at each step will result in a different search space.
