Third edition of Artificial Intelligence: foundations of computational agents, Cambridge University Press, 2023 is now available (including the full text).
4.8.2 Randomized Algorithms
Iterative best improvement randomly picks one of the best neighbors of the current assignment. Randomness can also be used to escape local minima that are not global minima in two main ways:
- random restart, in which values for all variables are chosen at random. This lets the search start from a completely different part of the search space.
- random walk, in which some random steps are taken interleaved with the optimizing steps. With greedy descent, this process allows for upward steps that may enable random walk to escape a local minimum that is not a global minimum.
A random walk is a local random move, whereas a random restart is a global random move. For problems involving a large number of variables, a random restart can be quite expensive.
A mix of greedy descent with random moves is an instance of a class of algorithms known as stochastic local search.
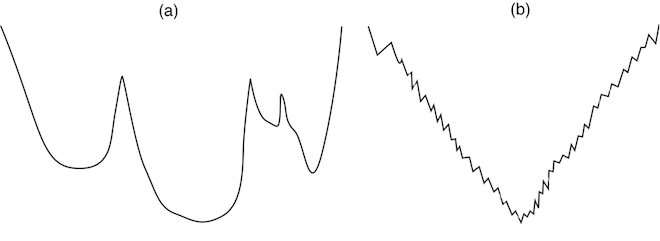
Unfortunately, it is very difficult to visualize the search space to understand what algorithms you expect to work because there are often thousands of dimensions, each with a discrete set of values. Some of the intuitions can be gleaned from lower-dimensional problems. Consider the two one-dimensional search spaces in Figure 4.7, where we try to find the minimum value. Suppose that a neighbor is obtained by a small step, either left or right of the current position. To find the global minimum in the search space (a), we would expect the greedy descent with random restart to find the optimal value quickly. Once a random choice has found a point in the deepest valley, greedy descent quickly leads to the global minimum. One would not expect a random walk to work well in this example, because many random steps are required to exit one of the local, but not global, minima. However, for search space (b), a random restart quickly gets stuck on one of the jagged peaks and does not work very well. However, a random walk combined with greedy descent enables it to escape these local minima. One or two random steps may be enough to escape a local minimum. Thus, you would expect that a random walk would work better in this search space.
As presented, the local search has no memory. It does not remember anything about the search as it proceeds. A simple way to use memory to improve a local search is a tabu list, which is a list of the most recently changed variable-value assignments. The idea is, when selecting a new assignment, not to select a variable-value pair that is on the tabu list. This prevents cycling among a few assignments. A tabu list is typically of a small fixed size; the size of the tabu list is one of the parameters that can be optimized. A tabu list of size 1 is equivalent to not allowing the same assignment to be immediately revisited.
Algorithms can differ in how much work they require to guarantee the best improvement step. At one extreme, an algorithm can guarantee to select a new assignment that gives the best improvement out of all of the neighbors. At the other extreme, an algorithm can select a new assignment at random and reject the assignment if it makes the situation worse. The rest of this section gives some typical algorithms that differ in how much computational effort they put in to ensure that they make the best improvement. Which of these methods works best is, typically, an empirical question.
