Third edition of Artificial Intelligence: foundations of computational agents, Cambridge University Press, 2023 is now available (including the full text).
4.8.3 Evaluating Randomized Algorithms
It is difficult to compare randomized algorithms when they give a different result and a different run time each time they are run, even for the same problem. It is especially difficult when the algorithms sometimes do not find an answer; they either run forever or must be stopped at an arbitrary point.
Unfortunately, summary statistics, such as the mean or median run time, are not very useful. For example, if you were to compare algorithms on the mean run time, you must consider how to average in unsuccessful runs (where no solution was found). If you were to ignore these unsuccessful runs in computing the average, then an algorithm that picks a random assignment and then stops would be the best algorithm; it does not succeed very often, but when it does, it is very fast. If you were to treat the non-terminating runs as having infinite time, then all algorithms that do not find a solution will have infinite averages. If you use the stopping time as the time for the non-terminating runs, the average is more of a function of the stopping time than of the algorithm itself, although this does allow for a crude trade-off between finding some solutions fast versus finding more solutions.
If you were to compare algorithms using the median run time, you would prefer an algorithm that solves the problem 51% of the time but very slowly over one that solves the problem 49% of the time but very quickly, even though the latter is more useful. The problem is that the median (the 50th percentile) is just an arbitrary value; you could just as well consider the 47th percentile or the 87th percentile.
One way to visualize the run time of an algorithm for a particular problem is to use a run-time distribution, which shows the variability of the run time of a randomized algorithm on a single problem instance. On the x-axis is either the number of steps or the run time. The y-axis shows, for each value of x, the number of runs or proportion of the runs solved within that run time or number of steps. Thus, it provides a cumulative distribution of how often the problem was solved within some number of steps or run time. For example, you can find the run time of the 30th percentile of the runs by finding the x-value that maps to 30% on the y-scale. The run-time distribution can be plotted (or approximated) by running the algorithm for a large number of times (say, 100 times for a rough approximation or 1,000 times for a reasonably accurate plot) and then by sorting the runs by run time.
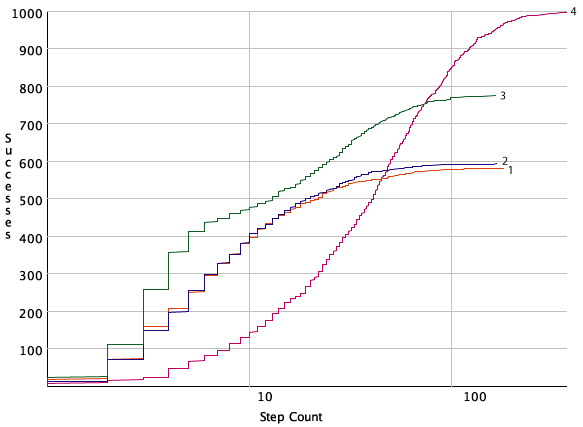
One algorithm strictly dominates another for this problem if its run-time distribution is to the left (and above) the run-time distribution of the second algorithm. Often two algorithms are incomparable under this measure. Which algorithm is better depends on how much time you have or how important it is to actually find a solution.
A run-time distribution allows us to predict how the algorithm will work with random restart after a certain number of steps. Intuitively, a random restart will repeat the lower left corner of the run-time distribution, suitably scaled down, at the stage where the restart occurs. A random restart after a certain number of greedy descent steps will make any algorithm that sometimes finds a solution into an algorithm that always finds a solution, given that one exists, if it is run for long enough.
By looking at the graph, you can see that Algorithm 3 can often solve the problem in its first four or five steps, after which it is not as effective. This may lead you to try to suggest using Algorithm 3 with a random restart after five steps and this does, indeed, dominate all of the algorithms for this problem instance, at least in the number of steps (counting a restart as a single step). However, because the random restart is an expensive operation, this algorithm may not be the most efficient. This also does not necessarily predict how well the algorithm will work in other problem instances.
