Third edition of Artificial Intelligence: foundations of computational agents, Cambridge University Press, 2023 is now available (including the full text).
10.2.3 Multiagent Decision Networks
The extensive form of a game can be seen as a state-based representation of a game. As we have seen before, it is often more concise to describe states in terms of features. A multiagent decision network is a factored representation of a multiagent decision problem. It is like a decision network, except that each decision node is labeled with an agent that gets to choose a value for the node. There is a utility node for each agent specifying the utility for that agent. The parents of a decision node specify the information that will be available to the agent when it has to act.
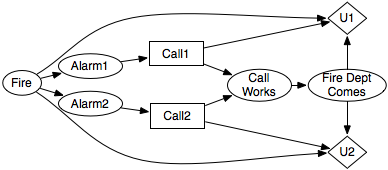
A multiagent decision network can be converted into a normal-form game; however, the number of strategies can be enormous. If a decision variable has d states and n binary parents, there are 2n assignments of values to parents and so d2n strategies. That is just for a single decision node; more complicated networks are even bigger when converted to normal form. Therefore, the algorithms that we present that are exponential in the number of strategies are impractical for anything but the smallest multiagent decision networks.
Other representations exploit other structures in multiagent settings. For example, the utility of an agent may depend on the number of other agents who do some action, but not on their identities. An agent's utility may depend on what a few other agents do, not directly on the actions of all other agents. An agent's utility may only depend on what the agents at neighboring locations do, and not on the identity of these agents or on what other agents do.
