Third edition of Artificial Intelligence: foundations of computational agents, Cambridge University Press, 2023 is now available (including the full text).
10.4 Partially Observable Multiagent Reasoning
Partial observability means that an agent does not know the state of the world or that the agents act simultaneously.
Partial observability for the multiagent case is more complicated than the fully observable multiagent case or the partially observable single-agent case. The following simple examples show some important issues that arise even in the case of two agents, each with a few choices.
 |
| ||||||||||||||||||||
If the kicker kicks to his right and the goalkeeper jumps to his right, the probability of a goal is 0.9, and similarly for the other combinations of actions, as given in the figure.
What should the kicker do, given that he wants to maximize the probability of a goal and that the goalkeeper wants to minimize the probability of a goal? The kicker could think that it is better kicking to his right, because the pair of numbers for his right kick is higher than the pair for the left. The goalkeeper could then think that if the kicker will kick right, then he should jump left. However, if the kicker thinks that the goalkeeper will jump left, he should then kick left. But then, the goalkeeper should jump right. Then the kicker should kick right.
Each agents is potentially faced with an infinite regression of reasoning about what the other agent will do. At each stage in their reasoning, the agents reverse their decision. One could imagine cutting this off at some depth; however, the actions then are purely a function of the arbitrary depth. Even worse, if the kicker knew the depth limit of reasoning for the goalkeeper, he could exploit this knowledge to determine what the kicker will do and choose his action appropriately.
An alternative is for the agents to choose actions stochastically. You could imagine that the kicker and the goalkeeper each secretly toss a coin to decide what to do. You then should think about whether the coins should be biased. Suppose that the kicker decides to kick to his right with probability pk and that the goalkeeper decides to jump to his right with probability pj. The probability of a goal is then
0.9 pk pj + 0.3 pk (1-pj) + 0.2 (1-pk) pj + 0.6 (1-pk)(1-pj).
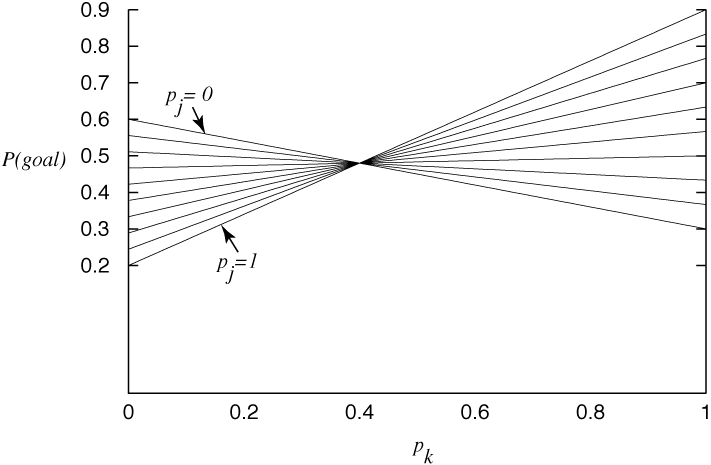
Figure 10.8 shows the probability of a goal as a function of pk. The different lines correspond to different values of pj.
There is something special about the value pk=0.4. At this value, the probability of a goal is 0.48, independent of the value of pj. That is, no matter what the goalkeeper does, the kicker expects to get a goal with probability 0.48. If the kicker deviates from pk=0.4, he could do better or he could do worse, depending on what the goalkeeper does.
The plot for pj is similar, with all of the lines meeting at pj=0.3. Again, when pj=0.3, the probability of a goal is 0.48.
The strategy with pk=0.4 and pj=0.3 is special in the sense that neither agent can do better by unilaterally deviating from the strategy. However, this does not mean that they cannot do better; if one of the agents deviates from this equilibrium, the other agent can do better by deviating from the equilibrium. However, this equilibrium is safe for an agent in the sense that, even if the other agent knew the agent's strategy, the other agent cannot force a worse outcome for the agent. Playing this strategy means that an agent does not have to worry about double-guessing the other agent. He will get the best payoff he can guarantee to obtain.
Let us now extend the definition of a strategy to include randomized strategies.
Consider the normal form of a game where each agent gets to choose an action simultaneously. Each agent chooses an action without knowing what the other agents choose.
A strategy for an agent is a probability distribution over the actions for this agent. If the agent is acting deterministically, one of the probabilities will be 1 and the rest will be 0; this is called a pure strategy. If the agent is not following a pure strategy, none of the probabilities will be 1, and more than one action will have a non-zero probability; this is called a stochastic strategy. The set of actions with a non-zero probability in a strategy is called the support set of the strategy.
A strategy profile is an assignment of a strategy to each agent. If σ is a strategy profile, let σi be the strategy of agent i in σ, and let σ-i be the strategies of the other agents. Then σ is σiσ-i. If the strategy profile is made up of pure strategies, it is often called an action profile, because each agent is playing a particular action.
A strategy profile σ has a utility for each agent. Let utility(σ,i) be the utility of strategy profile σ for agent i. The utility of a stochastic strategy profile can be computed by computing the expected utility given the utilities of the basic actions that make up the profile and the probabilities of the actions.
A best response for an agent i to the strategies σ-i of the other agents is a strategy that has maximal utility for that agent. That is, σi is a best response to σ-i if, for all other strategies σi' for agent i,
utility(σiσ-i,i) ≥ utility(σi'σ-i,i).
A strategy profile σ is a Nash equilibrium if, for each agent i, strategy σi is a best response to σ-i. That is, a Nash equilibrium is a strategy profile such that no agent can be better by unilaterally deviating from that profile.
One of the great results of game theory, proved by Nash, Jr. (1950)Nash, is that every finite game has at least one Nash equilibrium.
There are examples with multiple Nash equilibria. Consider the following two-agent, two-action game.
| Agent 2 | |||
| dove | hawk | ||
| Agent 1 | dove | R/2,R/2 | 0,R |
| hawk | R,0 | -D,-D | |
In this matrix, Agent 1 gets to choose the row, Agent 2 gets to choose the column, and the payoff in the cell is a pair consisting of the reward to Agent 1 and the reward to Agent 2. Each agent is trying to maximize its own reward.
In this game there are three Nash equilibria:
- In one equilibrium, Agent 1 acts as a hawk and Agent 2 as a dove. Agent 1 does not want to deviate because then they have to share the resource. Agent 2 does not want to deviate because then there is destruction.
- In the second equilibrium, Agent 1 acts as a dove and Agent 2 as a hawk.
- In the third equilibrium, both agents act stochastically. In this equilibrium, there is some chance of destruction. The probability of acting like a hawk goes up with the value R of the resource and goes down as the value D of destruction increases. See Exercise 10.1.
In this example, you could imagine each agent doing some posturing to try to indicate what it will do to try to force an equilibrium that is advantageous to it.
Having multiple Nash equilibria does not come from being adversaries, as the following example shows.
| Agent 2 | |||
| football | shopping | ||
| Agent 1 | football | 2,1 | 0,0 |
| shopping | 0,0 | 1,2 | |
In this matrix, Agent 1 chooses the row, and Agent 2 chooses the column.
In this game, there are three Nash equilibria. One equilibrium is where they both go shopping, one is where they both go to the football game, and one is a randomized strategy.
This is a coordination problem. Knowing the set of equilibria does not actually tell either agent what to do, because what an agent should do depends on what the other agent will do. In this example, you could imagine conversations to determine which equilibrium they would choose.
Even when there is a unique Nash equilibrium, that Nash equilibrium does not guarantee the maximum payoff to each agent. The following example is a variant of what is known as the prisoner's dilemma.
- taking $100 for yourself or
- giving $1,000 to the other person.
This can be depicted as the following payoff matrix:
| Player 2 | |||
| take | give | ||
| Player 1 | take | 100,100 | 1100,0 |
| give | 0,1100 | 1000,1000 | |
No matter what the other agent does, each agent is better off if it takes rather than gives. However, both agents are better off if they both give rather than if they both take.
Thus, there is a unique Nash equilibrium, where both agents take. This strategy profile results in each player receiving $100. The strategy profile where both players give results in each player receiving $1,000. However, in this strategy profile, each agent is rewarded for deviating.
There is a large body of research on the prisoner's dilemma, because it does not seem to be so rational to be greedy, where each agent tries to do the best for itself, resulting in everyone being worse off. One case where giving becomes preferred is when the game is played a number of times. This is known as the sequential prisoner's dilemma. One strategy for the sequential prisoner's dilemma is tit-for-tat: each player gives initially, then does the other agent's previous action at each step. This strategy is a Nash equilibrium as long as there is no last action that both players know about. [See Exercise 10.3.]
Having multiple Nash equilibria not only arises from partial observability. It is even possible to have multiple equilibria with a perfect information game, and it is even possible to have infinitely many Nash equilibria, as the following example shows.
Suppose the sharing game were modified slightly so that Andy offered a small bribe for Barb to say "yes." This can be done by changing the 2,0 payoff to be 1.9,0.1. Andy may think, "Given the choice between 0.1 and 0, Barb will choose 0.1, so then I should keep." But Barb could think, "I should say no to 0.1, so that Andy shares and I get 1." In this example (even ignoring the rightmost branch), there are multiple pure Nash equilibria, one where Andy keeps, and Barb says yes at the leftmost branch. In this equilibrium, Andy gets 1.9 and Barb gets 0.1. There is another Nash equilibrium where Barb says no at the leftmost choice node and yes at the center branch and Andy chooses share. In this equilibrium, they both get 1. It would seem that this is the one preferred by Barb. However, Andy could think that Barb is making an empty threat. If he actually decided to keep, Barb, acting to maximize her utility, would not actually say no.
The backward induction algorithm only finds one of the equilibria in the modified sharing game. It computes a subgame-perfect equilibrium, where it is assumed that the agents choose the action with greatest utility for them at every node where they get to choose. It assumes that agents do not carry out threats that it is not in their interest to carry out at the time. In the modified sharing game of the previous example, it assumes that Barb will say "yes" to the small bribe. However, when dealing with real opponents, we must be careful of whether they will follow through with threats that we may not think rational.
